
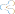
设计和评估用于本地代码搜索的多推荐系统
Xi Ge and David C. Shepherd and Kostadin Damevski and Emerson R. Murphy-Hill. Design and evaluation of a multi-recommendation system for local code search. Journal of Visual Languages and Computing, 2017, 39:1--9.
摘要在软件维护过程中,通常会在本地代码库中搜索相关代码。然而,研究表明 88%的手动搜索查询均未检索到任何相关结果。搜索失败的原因之一是现有搜索工具对字符串匹配算法的依赖,该算法无法找到与语义相关的代码。为了帮助开发人员编写更好的查询来解决此问题,研究人员提出了许多查询推荐技术,这些技术依赖于各种字典和算法。但是,这些技术中很少有来自实际开发人员的使用数据进行评估的。为了填补这一空白,我们设计了一种基于多种查询推荐技术协作的推荐系统。我们在 Sando 代码搜索工具中实施并部署了此推荐系统,并进行了纵向调查。我们的研究表明,超过 34%的查询结果采用来自推荐系统;拓建查询检索结果与手动查询相比高出 11%。
1. 介绍许多编程都是从搜索开始的。但搜索代码其实困难:许多人被迫使用过时的工具(例如基于正则表达式的搜索工具)来搜索他们从未见过的数百万行代码。由于这些工具仅取决于开发人员编写的查询与陌生字符串的匹配程度,因此这些工具的查询中有 88%没有返回相关结果。而开发人员将 40%的时间用于搜索、导航、阅读和理解源代码,这些失败的搜索会浪费大量开发人员的时间,进而增加软件开发成本。
本地代码搜索工具可帮助开发人员找到编程任务的起点。这类工具常作为主流集成开发环境(IDE)的一部分:如 InstaSearch 和 Sando 分别可用于 Eclipse 和 Visual Studio 。这些工具将开发人员的查询作为输入,并从 IDE 当前打开的项目中检索代码元素。研究表明,本地代码搜索工具比正则表达式搜索工具更有效,并且已经观察到许多开发人员每天都频繁使用这种工具。本地代码搜索工具与 grep 等正则表达式搜索工具不同在于:(1)检索代码元素(例如方法,类和字段),而不是文本行;(2)返回排名结果,使相关性越高的结果越易于访问;(3)在开发人员搜索前对代码库进行索引,从而使搜索几乎是即时的。
尽管有这些优点,本地代码搜索工具仍存在某些与正则表达式搜索工具相同的问题。例如,假设开发人员想要搜索用户名在身份验证系统中的存储方式。他们可以搜索“user file”或“user element”。但是,该实现可能将存储称为“user document”。如果不了解代码库中使用的确切术语,开发人员将不会考虑编写此查询语句。在这种情况下,正则表达式搜索工具和本地代码搜索工具都不会对开发人员有所帮助。
为了解决这个问题,研究人员提出了多种查询推荐技术。但是,在实际环境中,对这些技术的研究很少。如果不观察开发人员与推荐技术的实际交互,则不清楚这些技术的可用性和实用性。为了填补这一空白,我们实施了 Coronado,这是 Sando 搜索工具的扩展,该工具集成了各种推荐技术,帮助开发人员撰写新查询并优化失败的查询。利用 Sando 的广受欢迎,我们能够通过收集现场数据来评估这些推荐技术。总体来说,本文的贡献是:
多种查询推荐技术的实现,作为对 Sando 的扩展。调查了 Coronado 的可用性和实用性。我们收集了来自 591 位的 24 个月的 Sando 用户使用情况数据。最终表明,在手动搜索之前或之后推荐查询同样有用,推荐代码库中的标识符是最为有效。2. Sando 推荐在介绍推荐技术之前,我们首先介绍一下名为 Sando 的本地代码搜索工具,该工具可以实现和评估我们的技术。作为 Visual Studio 插件,Sando 允许开发人员通过发送与 Google 查询类似的查询,在本地代码库中搜索代码片段。 Sando 支持对 C 和 C#代码的搜索。它将不同级别的软件实体视为文档,包括类,方法和字段。搜索结果是包含查询术语的文档列表。 Sando 根据“文档频率反比”得分对结果进行排序,这些得分反映了术语在文档集中对文档的重要性。图 1 是 Sando 的屏幕截图,其中搜索框在顶部(A),底部的列表视图(B)呈现搜索结果。在搜索框附近,云按钮基于标签云调用推荐技术,“ [C]”按钮清除搜索历史,“ [?]”按钮提供帮助。
当用户单击某一搜索结果时,Sando 将弹出一个窗口,以向其提供相应代码元素的概述。弹出窗口的下半部分(C)包含整个代码元素,而上半部分(D)包含查询词的确切行。双击结果可打开包含搜索结果的文件。
Sando 推荐系统将交互式查询推荐技术与半自动查询修改和扩展技术交织在一起,帮助用户构建初始查询,该技术旨在帮助用户重新构造可能产生较差结果的初始查询。在本文中,我们将第一组推荐称为 pre-search,将第二组推荐(在初始查询后出现)称为 post-search。在这两种情况下,Sando 都遵循典型推荐系统的精神,依靠用户反馈来手动选择、修改或扩展提交给系统的查询词。通常这种明确的用户交互比完全自动化的查询扩展系统能产生更准确的结果。
基于以下原因,我们将 Sando 用作实现和评估推荐技术的平台:(1)Sando 代表了本地代码搜索工具,因为它实现了与其他集成开发环境中的搜索工具类似的功能;(2)Sando 是具有可扩展 API 的开源项目,我们可以轻松地向其中添加功能;(3)Sando 的用户下载超过一万五千次,这为我们提供了大量可收集反馈的用户。
2.1 组件为了弥合本地代码搜索用户与正在搜索的代码库间的认知鸿沟,我们实现了名为 Coronado 的 Sando 扩展,该扩展基于五个组成部分:代码库术语,术语共现矩阵,Verb-Direct-Object 存储库,软件工程同义词库和英语词库。在解释 Coronado 如何使用这些组件推荐查询之前,我们首先讨论每个组件以及 Coronado 如何收集和维护这些内容。
2.1.1 代码库术语Coronado 的第一个组件包含了代码库中正在被搜索的术语。当 Sando 的索引器遍历开发者的项目时,Coronado 会收集这些术语。Sando 索引建立过程将源代码元素拆分为一组术语,包括原始标识符和驼峰命名拆分后的术语。例如,Sando 将方法名称“ parseFile”索引为三个术语:“ parse”,“ file”和“ parseFile”。C 和 C#关键字不建索引。
Sando 分两个阶段对代码库进行索引:初始索引和增量索引。仅当开发人员打开未被 Sando 缓存的项目时,Sando 才执行初始索引。每当开发人员更改已缓存的项目时,Sando 会执行增量索引。最初为 10,000 行代码的项目建立索引需要花费约 20 秒的时间,而为已更改的 C#文件逐步建立索引只要花费约 20 毫秒的时间。通过重新使用索引期间收集的术语,Coronado 可以在代码库中构建和维护术语集。
2.1.2 术语共现矩阵Coronado 的第二个组件是一个矩阵,该矩阵记录两个术语的共现次数。对于在源文档中一起出现的每对术语[t1;t2],矩阵生成器会将矩阵[t1; t2]处元素的当前值加 1。举个例子,考虑下面的代码片段:
PathManager CreatePathManager(string path) { if(Path.HasExtension(path)) return new PathManager(Path.GetDirectoryName(path)); else return new PathManager(path);}该方法包含以下十二个术语:path, manager, PathManager, create, CreatePathManager, has, extension, HasExtension, get, directory, name, 和 GetDirectoryName。因此,对于这种方法,同时出现的术语对是任意两项的组合;总共是 144(12*12)。当开发人员将此方法添加到代码库中时,术语共现矩阵会将与每对对应的元素的当前值加一,例如,fcreate,pathg,fpath,managerg 等元素。
一个问题是将共现矩阵保存在内存中效率低下。例如,考虑一下 Sando 本身,这是一个包含约 10,000 行代码和约 2000 个术语的项目。对于这样的项目,矩阵中的元素数量约为 400 万(2000*2000)。为了提高存储效率,我们利用了共生矩阵通常稀疏这一事实。也就是说,根据我们的工具使用数据,矩阵中超过 90%的元素包含 0 值。因此,我们通过使用 Yale 格式表示共现矩阵,Yale 格式是一种有效存储稀疏矩阵而几乎不存储数据的数据结构,且几乎不影响查找和插入的速度。
Yale 格式通过使用三个数组表示一个稀疏矩阵:(1)矩阵中所有非零元素的值都以行形式存储;(2)矩阵行的第一个非零元素的索引数组;(3)数组元素的列索引数组。图 2 给出了 Yale 格式的例子,其中 A,IA 和 JA 分别对应于上述三个数组。矩阵中的零点越多,Yale 格式提高存储效率的作用就越大。
2.1.3 Verb-Direct-Object 存储库Coronado 技术中的另一个组件是 Verb-Direct-Object 存储库。基于源代码通常涉及对对象执行操作,Fry 和同事提出了一种结合自然语言处理和源代码分析的技术。他们的技术从代码库,例如“打开文件”或“关闭流”中提取动词-对象对。通过采用此技术,Coronado 会定期分析代码库,提取动词-对象对,并将其缓存以备将来使用。
2.1.4 软件工程同义词库Coronado 还使用软件开发中经常使用的术语表。软件工程已经发展出自己的术语、同义词和缩写集,而这些术语、同义词和缩写集在常规英语(例如“imap”)中不存在。一些软件工程术语具有不同于其常规英语含义的特定含义,例如“class”。因此,简单地重用通用同义词库将无助于解释特定字段的信息,甚至可能有害于客户端软件工具。为了建立特定领域的词库,我们利用 Gupta 和同事们的工作,该工作在源代码中挖掘不同术语之间的关系,并生成 1724 对语义相关的术语。在这些术语对中,有 91%是特定于软件工程领域的同义词。这些特定字段的同义词的示例包括“execute”-“invoke”, “load”-“initialize”以及“instantiate”-“create”。此外,他们的工作还量化了同义词对的共性。例如,已经发现“create”与几个术语相关,包括“make”, “do”, 和“construct”。但是,“make”与“create”的关系要比与“construct”或“do”的关系更紧密。
2.1.5 英语同义词库Coronado 的最后一部分是通用的英语词库。为了建立这个词库,我们重用了 Miller 的词汇数据库 WordNet。WordNet 将相关概念表示为图,其中节点是单词,边将具有相似含义的单词连接起来。由于 Coronado 只是在寻找给定单词的邻居,因此使用 WordNet 查找同义词需要花费恒定的时间。尽管 WordNet 包含完整的英语单词集,但是将整个数据集保存在内存中的成本很高。因此,我们减少了 WordNet 的大小只包含英语中最常用的 10 万个单词。 我们推测 10 万个单词足以满足大多数查询的需求,尽管用户查询不寻常单词的频率仍然是一个悬而未决的问题,出于隐私原因,我们不收集有关 Sando 用户正在搜索的术语数据。
2.2 搜索前推荐接下来,我们描述 Coronado 如何使用这些组件。每当开发人员在 Sando 的搜索框中键入内容时,Coronado 都会在开发人员单击搜索按钮之前就推荐查询,如图 3 所示。我们称这些为搜索前推荐。这些推荐来自三个来源:标识符,Verb-Direct-Object 对和共同出现的术语。
由于在搜索框中每按一次键,就会向用户显示搜索前的推荐,因此查询的响应时间对其可用性至关重要。对于大型代码库(例如 Linux 内核),我们测试搜索前推荐生成响应时间约为秒级,这肯定会影响 Sando 的可用性。像许多其他搜索工具一样,我们发现从推荐术语中预生成 trie 数据结构可以将响应时间缩短几个数量级,但所需的额外内存和 CPU 时间却相对较少。
2.2.1 标识符搜索前推荐的第一个来源是标识符。当程序员在搜索框中键入字符串时,Coronado 将遍历代码库术语组件以确定该字符串是否为本地术语中任何标识符的前缀。然后推荐使用每个匹配的标识符来完成开发者的搜索查询,并在搜索框下方的下拉菜单中显示该标识符。 例如,图 3a 显示了当开发人员在 Family 上搜索时键入字符串“ update”时,向开发人员推荐的搜索词。Showcodebase 是一个开放源代码项目,允许用户构建 Family Tree。
2.2.2 Verb-Direct-Object 对当开发人员在搜索框中输入动词后按下空格键时,Sando 将从存储库组件中检索动词是否对应到 Verb-Direct-Object 对。如果 Sando 找到多个 Verb-Direct-Object 对,则 Sando 使用共现矩阵对它们进行排序;动词和直接宾语出现的次数越多,该对出现在下拉框中的位置就越靠前。当开发人员在搜索框中输入“update”时,图 3b 中的下拉菜单示例了 Verb-Direct-Object 推荐。因为“update”相比其他对象更常与“Status”同时出现。因此,“update Status”是最为推荐的搜索查询
2.2.3 频繁共现术语第三种搜索前推荐通过使用术语共现矩阵来推荐频繁共现的术语。在搜索框中输入一个或多个术语后,开发人员可以单击搜索框附近的云按钮以显示标签云。标签云中的术语是与搜索框中的术语最常共现的术语。标签云中的字体越大,则该词与搜索框中的词共现频率越高。图 3c 显示了一个示例—该标签云显示的术语与“parent”经常同时出现。 “children”一词与“parent”比“define”更常见。单击标签云中的术语可将其添加到原始搜索查询的末尾。
对于频繁出现的术语,我们选择在标签云中可视化术语,而不是像标识符和 Verb-Direct-Object 对那样的常规下拉列表。我们之所以选择这个选项,是因为早期实验表明,对于给定的代码库,与标识符或 Verb-Direct-Object 对相比,共现术语更多。因此,由于标签云比下拉列表能更有效地使用屏幕空间,因此我们使用这种方式来共现术语。在之后的讨论中,我们将频繁出现的术语称为标签云推荐。
2.3 搜索后推荐除了帮助开发人员完成查询之外,Coronado 还在开发人员单击搜索按钮并且未返回搜索结果后给出建议。在这种情况下,开发人员的查询包含了代码库中不存在的术语。为了帮助她编写新查询,Coronado 根据代码库术语、软件工程词库和英语词库在搜索中推荐代码库中语义相似的术语。假设原始查询具有多个以空格分隔的术语,那么 Coronado 首先查询代码库术语组件以检查代码库中每个术语是否存在。如果不存在则搜索失败,那么 Coronado 使用以下三个步骤来生成新查询。
2.3.1 预处理尽管代码库中不存在某个术语,但该术语的某些部分可能会存在。因此,Coronado 贪婪地拆分该术语,并将本地术语中存在的部分合并到推荐的查询中。更具体地说,对于查询中的给定术语,Coronado 会尝试查找本地术语中存在的最长前缀和后缀,而后以递归方式拆分术语的中间部分,直到找不到匹配的前缀或后缀。
例如,假设开发人员搜索“getelementname”,它在代码库中不存在。如果本地术语包含“get”和“name”,则将搜索到的术语拆分为三个新术语:“get”,“element”和“name”。
2.3.2 同义推荐拆分后,如果拆分词不存在于本地术语中,则 Coronado 会尝试在词库中找到它们的同义词。 Coronado 首先是软件工程词库,因为它的相关性比英语词库高。如果在软件工程同义词库中找不到同义词,则 Coronado 会尝试在英语同义词库中查找同义词。在检索同义词之后,该技术接下来将那些不在本地术语中的同义词排除在外。其余的同义词将被推荐给开发人员以代替原始术语。如果找到多个同义词进行推荐,Coronado 将使用 2.1 节中所述的术语“共现矩阵”对它们进行排名。输入查询的其他术语中出现频率更高的同义词排名更高。 我们在图 4 中说明了查找同义词的过程。
2.3.3 错词校正对于那些既不存在于本地术语中又不存在同义词库中的同义词的术语,Coronado 将其视为本地术语中的拼写错误。因此,Coronado 尝试更正它们。校正算法采用 2-gram 索引,可以快速找到与错误拼写相似的术语。
具体地说,此校正算法首先创建一个具有 416(26 * 26)行的校正表,其中每一行都用一对字母(从“ aa”,“ ab”,“ ac”到“ zz”)标记。接下来,对于本地的每个术语,Coronado 将该术语插入到表中其标签属于该术语一部分的行中。例如,假设术语“example”是本地术语,则插入到“ ex”,“ xa”,“ am”,“ mp”,“ pl”和“ le”的行中。插入完成后,Coronado 准备通过以下步骤使用此表来纠正给定的错误拼写:
对于错误拼写,我们首先计算其将插入的行。接下来,我们分析这些行中的现有术语,并找出与错误拼写共享行最多的术语,作为其更正。如果找到多个这样的术语,我们进一步选择距错误拼写编辑距离最小的那个作为校正术语。计算完搜索后推荐,Sando 在搜索框下显示推荐的查询。每个查询都是一个超链接,单击该链接将导致 Sando 搜索相应的查询,如图 5 所示。
3. 进一步工作通过改进和完善搜索推荐技术,可以在我们的工作基础上做进一步的研究。例如,未来的搜索工具可以使用兴趣度模型来更好地对推荐的查询进行排名,使用上下文信息来推荐与开发人员的近期活动相关的搜索查询。
改进推荐技术的第二种方法是为搜索中的软件集成特定领域的词汇知识。在当前的 Coronado 实施中,在开发人员的手动搜索失败后,我们仅使用软件工程词库和英语词库来推荐相关术语。我们相信特定领域的词库可以进一步提高推荐字词的质量。例如,如果开发人员在医学应用程序中进行搜索,则在医学领域推荐相关术语可能会导致更有希望的查询。
改善推荐效果的另一种方法是根据其他人员的成功查询向开发人员推荐查询。这样的技术可以利用相同代码库的开发人员的数据进行协同过滤,以推荐更好和更相关的查询。在开发更好的推荐技术之前,本地代码搜索工具的用户经验会有所帮助。分析日志文件固然可以挖掘使用模式,但无法理解开发人员行为的原因。例如,我们知道用户使用搜索前推荐的频率要比搜索后推荐的频率低,但如果不进行用户研究,我们就不知道为什么会这样。
推荐查询的另一个改善方面是让用户快速建立对推荐系统的信任,有几种实现此目标的方法,例如改善工具的用户界面,给出具体建议,演示或提供可见的外部学习材料。
致谢感谢国家重点研发计划课题:基于协同编程现场的智能实时质量提升方法与技术(2018YFB1003901)和国家自然科学基金项目:基于可理解信息融合的人机协同移动应用测试研究(61802171)支持!
本文由南京大学软件学院 2018 级硕士生袁阳阳翻译转述。
